Posted on 2019-07-26.
The “Array Manipulation” problem on HackerRank sounds simple. Starting with an array of zeros, you’re given a list of updates (“queries”) to make to the array. Each update consists of a start index and an end index, and a number that you’re supposed to add to all the elements between those indices. At the end, you just need to report the highest value in the array. The trick is doing this quickly for a large array and/or large number of updates. I’ll discuss a few solutions below.
My solutions are written in Kotlin.
I’ll just show how to implement the arrayManipulation function; for the main function, see the template that HackerRank provides.
Table of Contents:
The straightforward approach to this problem is:
That could be coded as follows:
fun arrayManipulation(n: Int, queries: Array<Array<Int>>): Long { val a = Array(n + 1) { 0L } for (q in queries) { for (i in q[0]..q[1]) { a[i] = a[i] + q[2] } } return a.max() ?: throw IllegalStateException() }
How will this perform? The outer loop will run M times (where M is the number of queries). For each query, the number of times the inner loop runs is equal to the number of elements covered by the query’s range. In the worst case, every query could specify the entire array as its range, in which case every iteration of the outer loop would run the inner loop N times (where N is the size of the array).
So, the overall time complexity is O(N*M). (Finding the max value at the end also takes O(N) time, but that’s a negligible addition to the O(N*M) that we’re already doing. If we were really concerned about it, we could optimize things by keeping track of the maximum as we go along instead.)
The maximum value of N is 107 and the maximum value of M is 2*105, so in the worst case an O(N*M) solution is running two trillion total iterations of the inner loop. That’s far too slow. If you submit this solution to HackerRank, it will solve about half the test cases; the rest will time out.
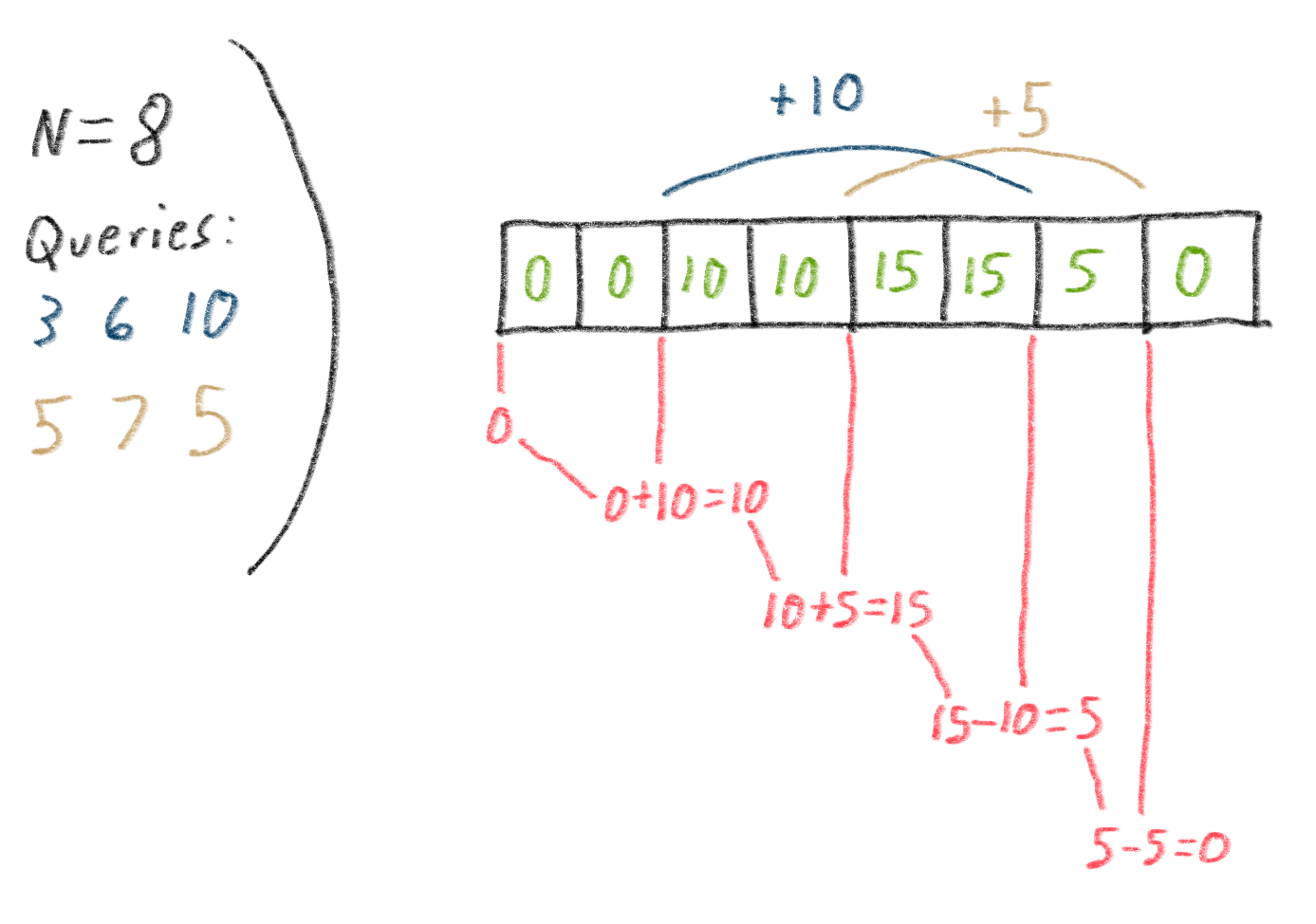
The diagram below shows a test case with array size N=8 and number of queries M=2. The first query says to add 10 to all elements between indices 3 and 6, and the second query says to add 5 to all elements between indices 5 and 7.
The boxes show the final values of each of the 8 elements in the array after both queries are processed. Above the array, the curving lines show the range that each of the queries affects; you can see that the value of each element is determined by summing up all the queries that overlap the element.
The markings in red below the array show an alternate way to view the problem. You can think of each index where a query begins or ends as a boundary at which the value in the array will change. Boundaries corresponding to the beginning of a query’s range cause the value to go up by the amount of the query, and boundaries corresponding to the end of a query’s range cause the value to go down by the amount of the query. (Notice that the number of boundaries is 2*M, so it’s impossible for there to be more than 2*M unique values in the final array, no matter what N is.)
If we come up with an efficient way to get all the boundaries in sorted order, we can then iterate through them to solve the problem, incrementing or decrementing a running sum as we go along. We’ll look at a couple similar ways of accomplishing this, which are both fast enough to pass all of HackerRank’s tests.
One approach is to build a sorted data structure containing all the boundaries. Sorting M elements can be accomplished in O(M*log(M)) time, and then all we’ll need to do is iterate through the resulting structure once.
The code below uses a TreeMap to keep track of all the boundaries, which will keep the structure sorted as we insert each boundary. We could also get broadly similar performance characteristics by building an unordered list of boundaries and then sorting it.
fun arrayManipulation(n: Int, queries: Array<Array<Int>>): Long { val addAt = TreeMap<Int, Long>() var max = 0L var sum = 0L for (q in queries) { addAt[q[0]] = q[2] + (addAt[q[0]] ?: 0L) addAt[q[1] + 1] = -q[2] + (addAt[q[1] + 1] ?: 0L) } for (add in addAt.values) { sum += add max = maxOf(sum, max) } return max }
This approach was brought to my attention by amansbhandari on the HackerRank discussion forum.
The indices of all the boundaries will be between 1 and N. If we have an array of size N, and store each boundary at its index in the array, then all the boundaries will be in order - they’ll just potentially have large swaths of empty elements between them. If we intiialized all those unused elements to 0 so they won’t affect our calculations, that’s fine. We can iterate over the whole array to calculate a running sum, exactly like in the solution shown above; it will take O(N) rather than O(M) time to do so.
Some of the forum posts refer to this as an O(N) solution, but that seems incorrect. It still has to loop over all M queries once to insert them into the array, and M could be greater than N for some test cases. Since there’s both an O(M) loop and an O(N) loop, the solution is O(N+M).
fun arrayManipulation(n: Int, queries: Array<Array<Int>>): Long { val addAt = Array(n + 2) { 0 } var max = 0L var sum = 0L for (q in queries) { addAt[q[0]] += q[2] addAt[q[1] + 1] -= q[2] } for (add in addAt) { sum += add.toLong() max = maxOf(sum, max) } return max }
Which is better, the O(M*log(M)) approach or the O(N+M) approach? Will one perform better on some inputs, and the other on other inputs?
For most of the allowed values of N and M, M*log(M) will be smaller than N+M. But when it isn’t, the Big-O analysis suggests the N+M solution will prevail. Note, though, that the way the O(M*log(M)) solution above is written, there will never be more than N+1 entries in the TreeMap1, so when N < M it might be better to describe that solution as O(M*log(N)). That further reduces the number of scenarios in which the O(N+M) approach wins.
But the Big-O notation intentionally ignores lots of details. The loops in the O(N+M) solution above are doing nothing but a few simple, efficient operations; the loops in the O(M*log(M)) solution are making method calls that deal with more complex data structures, which likely involve significantly more operations. So M*log(M) may need to be substantially larger than N+M before the O(M*log(M)) approach actually performs better.
Benchmarking is left as an exercise for the reader.